The CUDA programming model
CPU vs. GPU
Besides a Central Processing Unit (CPU), many computers nowadays also have a Graphic Processing Unit (GPU). Unlike CPU which is designed for sequential programs, the design of GPU is optimized for highly parallel computations involved in matrix multiplications during machine learning training process, mining cyptocurrencies, and the graphic performances of video games.
| CPU: Latency Oriented Design | GPU: Throughput Oriented Design | |
|---|---|---|
| Cache | Large cache | Small caches |
| Control | Complex flow control | Simple flow control |
| ALU | Powerful ALU | Energy efficient ALU |
The CPU aims to reduce the latency of sequential tasks on a single thread. The large cache can reduce the latency of loading the frequently accessed data, the sophisticated flow control and powerful ALU are designed to optimize the latency of the operation with large use of on chip memory and power.
In contrast, the GPU aims to devote the chip area and power to the massive floating point calculations. As pointed out by Kirk and Hwu, it takes more effort to reduce latency than to increase throughput based on chip area and power. The design of GPU is to maximize the execution throughput of massive numbers of parallel threads while allowing each thread to higher higher latency.
Since a program always has a mixed of sequential and parallel parts, the winning strategy is to use CPU when the latency is important (for example,
when the program is waiting for I/O) and use GPU when the throughput is important (for example, when the program is doing matrix multiplications).
GPU architecture
Physical Architecture

A GPU mainly consists of multiple Streaming Multiprocessors (SMs), the L2 cache, and the global memory.
- Streaming Multiprocessor (SM): The SM is the basic unit of a GPU. Each SM has warp schedulers, multiple CUDA cores (ALUs) each responsible for a thread, an L1 cache, and many other units.
- L2 cache: The L2 cache is a large cache shared by all SMs. It is used to reduce the latency of accessing the global memory.
- Global memory: The global memory is the main memory of the GPU. It is used to store data and instructions for the GPU. The global memory is large but has high latency.
Logical Architecture
SPMD model
The GPU launches a grid when executing a CUDA kernel. A grid is a 3D array of blocks and each block is a 3D array of threads. Each thread in a grid has a unique data input executing the same kernel function. This is the Single Program Multiple Data (SPMD) model of CUDA.
Identification of threads and blocks
Each thread in a block has a unique thread ID, and each block in a grid has a unique block ID.
The thread ID, block ID, and block dimension are used to identify the global location of a thread in a grid. For example, for a kernel with input array of length 2048, when block size is 256, the global location of thread 0 in block 1 is:
1 | int blockSize = 256; |
Memory Architecture
| memory hierarchy | permission | latency | scope | lifetime |
|---|---|---|---|---|
| Registers | RW | ~1 cycle | thread | thread |
| shared memory | RW | ~5 cycles | block | block |
| global memory | RW | ~500 cycles | application | application |
| constant memory | R | ~5 cycles with caching | application | application |
The shared memory resides on the L1 cache of each SM. It is shared among threads in a block.
As for the constant memory, it resides on the global memory but is cached in the L1 cache for each thread, achieving much lower latency.
Summary
In summary, how does the architecture of GPU work while executing a kernel with multiple threads?
When a kernel is launched like this from the host:
1 | kernel<<<gridDim, blockDim>>>(args); |
The threads are organized according to the grid dimension and block dimension. The CPU sends the kernel launch request to GPU.
When GPU receives the request, it loads the instructions for the kernel and starts allocating the necessary memory for the kernel execution and divides the thread blocks across available SMs.
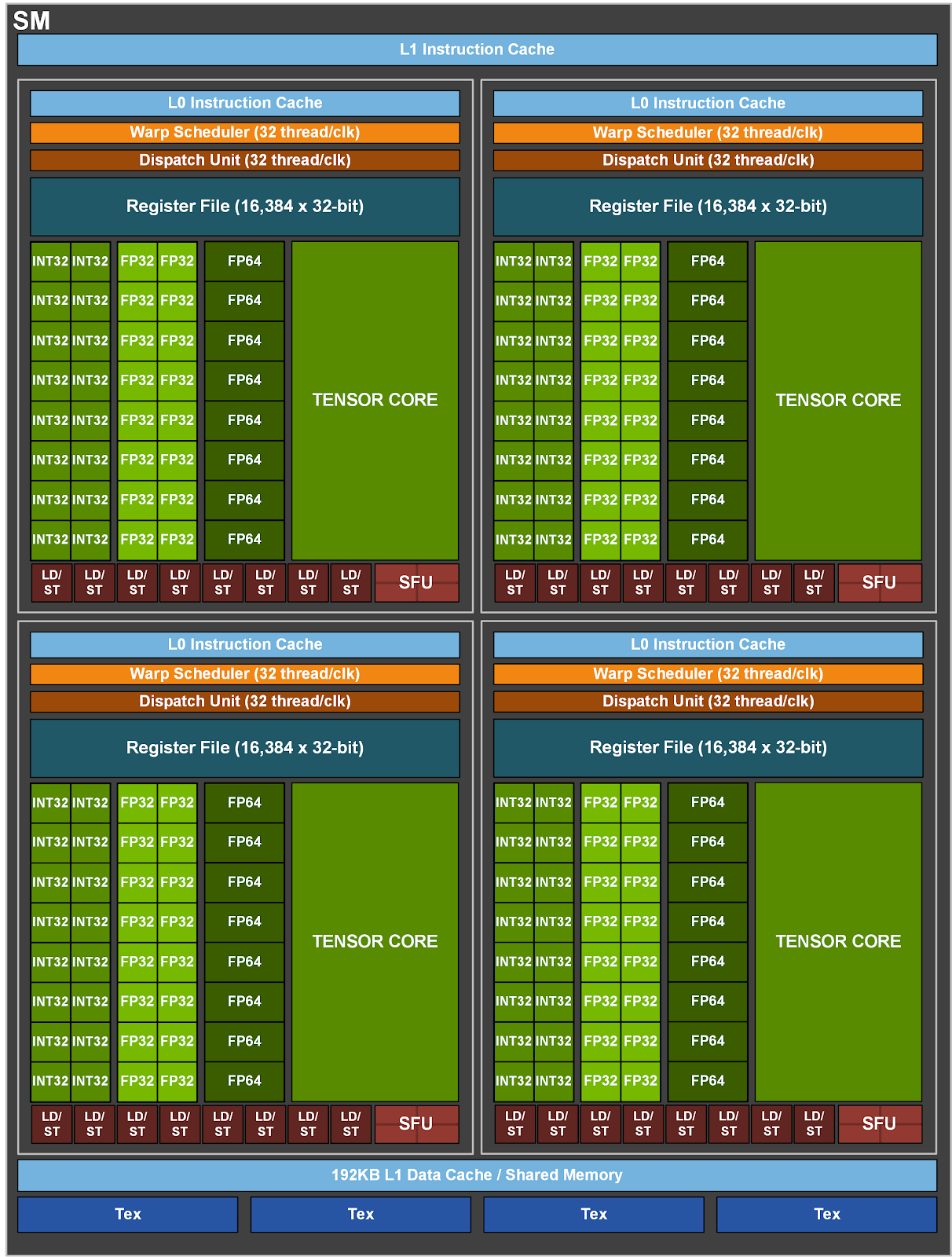
Each SM has a number of cores (the number depending on specific architectures), and each core is able to process the task of a thread. But before that, the threads are organized into warps. Each warp contains 32 threads. The Warps are scheduled and executed by the warp scheduler.
It is important not to confuse the warp with the thread block. A thread block can be larger than a warp, and a warp can contain multiple thread blocks depending on the dimensions. The block dimension is manually controlled by the programmer, while the warp of threads are organized internally.
Consecutive threads are typically grouped in one warp. Threads in the same warp are executing the same instruction at the same time.
branch divergence and predicated execution:
Branch Divergence occurs when threads within the same warp take different execution paths due to control conditions (e.g., if statements). This situation can lead to inefficiencies because the GPU’s SIMD (Single Instruction, Multiple Data) architecture is designed to execute the same instruction across all threads in a warp simultaneously. When threads diverge, the warp must execute each path serially, which can significantly reduce performance.
To mitigate the performance impact of branch divergence, GPUs utilize predicated execution. In this model, all threads in a warp evaluate the same instructions regardless of their individual conditions. However, only the threads that meet the condition (i.e., those for which the predicate is true) will write results or perform computations. Threads that do not meet the condition effectively skip the computation without stalling the entire warp
The block dimension matters for SM occupancy:
For a SM that can take up to 1536 threads and up to 4 blocks, what block size can achieve full occupancy?
For a block size of 256, there will be 1536 / 256 = 6 blocks, which is more than the maximum of 4 blocks. So the SM will only take 4 blocks and 1024 threads. The occupancy is 1024 / 1536 = 66.67%.
For a block size of 128, there will be 1536 / 128 = 12 blocks, which is more than the maximum of 4 blocks. So the SM will only take 4 blocks and 512 threads. The occupancy is 512 / 1536 = 33.33%.
For a block size of 384, there will be 1536 / 384 = 4 blocks, achieving 100% occupancy.
The warp scheduler inside the SM picks eligible warps. Each clock cycle, the SM issues one instruction per warp scheduler. However, the instruction might not execute right away. The warp might be stalled for multiple reasons like memory access. When a warp is stalled and not making progress, the SM can switch to other ready warps hiding latency.
Related quizes
SP2025 exam1
Given a heterogeneous CPU-GPU system, Hrishi and Colin are asked to deploy a benchmark program, which is developed by Vijay, to calibrate the A40 GPU performance.
The system has the following characteristics:
- Contains a single-core CPU and an A40 GPU
- The CPU is running under the clock at 3.8GHz, and the GPU is running under the boost mode
- Each multiply-add operation takes 3 CPU cycles or 460 GPU cycles per CUDA thread to complete on thi system.
The benchmark program has the following characteristics:
Parallel workload / Sequential workload = 2.00- On a CPU only system, both parallel and sequential workloads are done by the CPU, In this CPU-GPU system, the sequential workloads are only done by the CPU, and the parallel workloads are carried out only by the GPU.
- In this benchmark, all parallel and sequential workloads are multiply-add operations.
- The overall count of multiply-add operations executed on both the CPU-only and CPU-GPU systems is identical.
- GPU kernel is launched with
blockDim (7, 4, 4)and minimum GridDim for max SM occupancy. - CPU and GPU execution do not overlap, i.e., GPU execution starts only after CPU execution completes and vice versa.
- The benchmark program takes 33.12 seconds to finish on the CPU-only system, and you observe an overall speedup of 2.7824 on the CPU-GPU system.
Question 1 With the information above, how many CUDA threads are assigned in each SM?
Number of of threads per block: 7*4*4 = 112, which needs 4 warps.
maximum waprs per SM = 48, so maximum blocks per SM limited by number of warps is 48 / 4 = 12
maximum threads per SM = 1536, so maximum blocks per SM calculated by number of threads is 1536 / 112 = 13.8
So the number of threads per SM is 12 * 112 = 1344
Question 2 Calculate the combined duration of the kernel launch overhead and memory transfer inside the CPU-GPU system.
Number of CPU cycles: 33.12 * 3.8 = 125.856G
Number of instructions: 125.856 / 3 = 41.952G
The total number of instructions are the same for CPU-only and CPU-GPU system. According to this and the workload for CPU-GPU system, we can get
Number of instruction on GPU: 41.95w * 2/3 = 27.968G
Given that each multiply-add operation takes 460 GPU cycles, we can calculate:
Number of GPU cycles: 27.968 * 460 = 12865.28G
Given that under boost mode the GPU runs at 1.74GHz and with total of 84 SMs each SM is running 1344 threads, we can calculate:
GPU runtime: 12865.28 / (84 * 1344) / 1.74 = 0.06549s
Total runtime is 33.12 / 2.7824 = 11.9034s
The kernel launch overhead and memory transfer time is the total runtime minus the CPU and GPU runtime, which is 11.9034 - 0.06549 - 33.12 / 3 = 11.9034 - 0.06549 - 11.04 = 0.7979s
References
ECE408/CS483 University of Illinois at Urbana-Champaign
David Kirk/NVIDIA and Wen-mei Hwu, 2022, Programming Massively Parallel Processors: A Hands-on Approach
CUDA C++ Programming Guide
NVIDIA Ampere Architecture In-Depth
The CUDA programming model
http://gong208.github.io/2025/04/27/2025-4-27-GPUArchitecture/