2025-05-03-Reduction
What is reduction?
Reduction is an operation that applies on a set of inputs to get a single value.
A reduction uses a binary operator that is associative and commutative.
Associative means that the order of the operations does not matter, and coomutative means that the order of the operands does not matter.
Besides the binary operator, an identity value is also needed. For example, 0 is an identity value for addition, and 1 is an identity value for multiplication, etc.
Reduction tree
A reduction tree is a binary tree that is used to perform a reduction operation in parallel.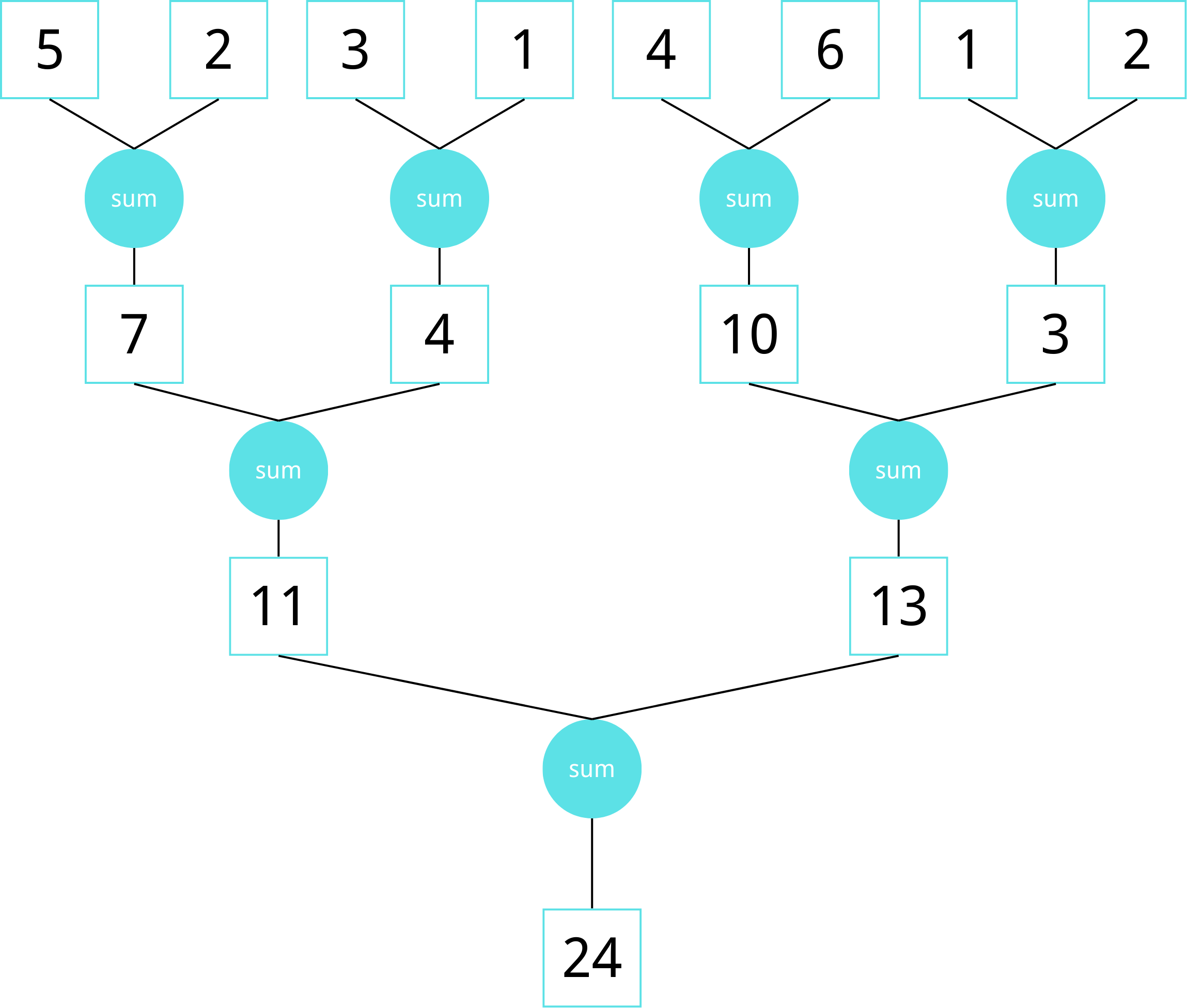
This tree takes \( log(N) \) steps and performs \( N - 1 \) operations
Naive CUDA reduction
data mapping
- For a block with M threads, it reads in 2M elements in shared memory.
- For each of the log(2M) steps, each thread
- performs one operation on two elements
- writes the result back to shared memory
In each thread we halve the number of active threads.
- Each block writes one final result back to global memory.

We use stride to control the number of active threads. We start from 1 and in each step we double it until we reach the number of elements in the block.
Active thread is controled by condition threadIdx.x % stride == 0, and each active thread will perform reduction on array[2*threadIdx.x] and array[2*threadIdx.x+stride] and writes the result to array[2*threadIdx.x].
1 | for (int stride = 1; stride < blockDim.x; stride *= 2) { |
- The final result is written to global memory by the first thread in each block. There will be
N/2Mpartial results in global memory. If the result is small enough, we perform it sequentially on CPU, otherwise we relaunch the kernel.
This is the process of segmented reduction.
Analysis
We notice that in each step a thread is eigher performing a reduction or idle.
Cocerning the control divergence, after the first step, all threads with odd indices are idle, causing divergence in each warp.
… After fifth step, there will be warps with all threads idle(no divergence) and some warps with only one thread active.
This Naive implementation is having serious divergence.
Improved reduction with data reassignment
In the naive implementation the poor divergence is caused by the fact that we are putting down the threads with indices that are not multiple of stride, so in each warp there will be divergence of active and idle threads.
To improve this, we can reassign the data such that we can keep the active threads consecutive.
Instead of starting form 1 and multiply by 2, we rather start from blockDim.x and divide by 2 in each step.

1 | __global__ void total(float *input, float *output, int len) { |
In this way, for the first six steps when stride is 1024, 512, 256, 128, 64, 32, the threads in each warp will be either active or idle with no divergence.
Further improvement
Currently the implementation is memory-bounded:
one operation for every 8B value read, we want to do utlize the shared memory more.
Currently a block with 1024 threads reads 2048 values, each SM has 64KB shared memory for A40 GPU. If we are launching 2 blocks per SM, we are only using 2048 * 2 * 4B = 16KB shared memory.
We can try to read 4096 or 8192 values to increase parallelism.
References
ECE408/CS483 University of Illinois at Urbana-Champaign
David Kirk/NVIDIA and Wen-mei Hwu, 2022, Programming Massively Parallel Processors: A Hands-on Approach
CUDA C++ Programming Guide
2025-05-03-Reduction